2020. 7. 3. 15:56ㆍdata structure/hash
1. Hash의 기본 개념
key와 value를 이용해 특정 데이터인 value를 고유 인덱스인 key로 관리하는 자료구조입니다.
내부적으로 배열을 사용해 데이터를 저장하기 때문에 빠른 검색 속도를 가지고 있습니다.
특별한 알고리즘(Hash Function)을 이용해 데이터와 관련한 고유의 숫자를 만들어 인덱스로 활용합니다.
특정 데이터가 저장되는 인덱스는 해당 데이터의 고유한 위치이기 때문에 삽입, 삭제 시 데이터의 이동이 없습니다.
2. Hash의 구조
Hash Table을 이용해 데이터를 저장합니다.
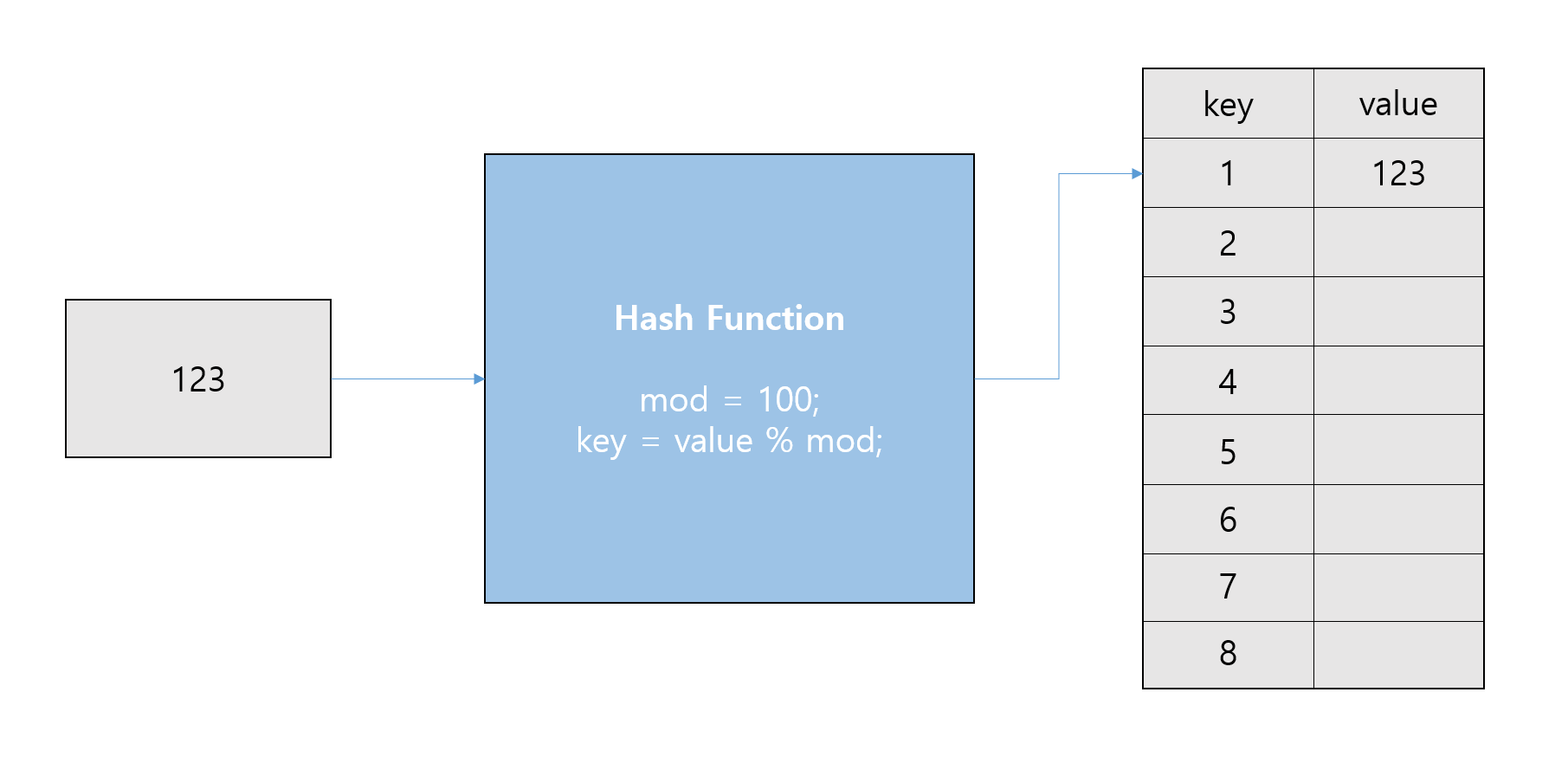
Hash Code / value
객체에 대응하는 고유의 정수값을 Hash Code라고 합니다.
데이터는 Hash Function을 거쳐 value에 저장되는데 이때 key(index) 값이 Hash Code 입니다.
Object Class에 정의된 메서드 hashCode()가 해당 객체의 Hash Code이고, 이는 두 객체가 같은 지 빠르게 판별하기 위해 사용하고 있습니다. 하지만, 다른 객체이더라도 같은 Hash Code 값을 가질 수 있습니다.
Hash Function
Hash Function을 구현하는 방법은 여러 가지가 있지만 가장 간단한 방법은 나머지 연산자를 이용하는 방법입니다.
3. Hash 충돌
Hash Function을 통해 Key 값을 뽑아내지만, 고유의 값이 아닌 중복된 Key 값이 나올 수 있습니다.
만약, Hash Code 값이 100과 101이 들어오고, Hash Function이 hashCode % mod=100 일 경우, 100과 101 모두 index가 1인 공간에 저장되게 됩니다.
이러한 Hash 충돌을 방지하기 위한 여러 가지 방법이 있습니다.
체이닝(Chaining)
충돌이 발생하면 각 데이터를 해당 주소에 있는 LinkedList에 삽입해 문제를 해결하는 방법입니다.
선형 탐사(Linear Probing)
해시 함수로부터 얻어낸 주소에 이미 다른 데이터가 입력되어 있을 때, 현재 주소에서 바로 다음 주소(탐사 이동 폭: 1)로 이동합니다.
제곱 탐사(Quadratic Probing)
해시 함수로부터 얻어낸 주소에 이미 다른 데이터가 입력되어 있을 때, 현재 주소에서 제곱 수를 탐사 이동 폭으로 다음 주소로 이동합니다.
이중 해싱(Double Hashing)
Hash Function을 이중으로 두어 하나는 최초의 주소를 얻고, 다른 하나는 충돌이 발생했을 때 탐사 이동 폭을 얻기 위해 사용합니다.
재해싱(Rehashing)
Hash Table의 크기를 늘리고, 크기에 맞춰 테이블 내 모든 데이터를 다시 해싱하는 방법입니다.